
Point Archivist at any legacy system - emails, spreadsheets, databases, PDFs. AI discovers the structure, you approve the schema, and extraction runs automatically. Then ask questions like you'd ask a colleague.
Request DemoFour steps from dark archive to queryable data. AI does the heavy lifting, you stay in control.
AI scans your messy source data and maps every field, format, and relationship.
A clean schema is designed and presented for your review. You approve, edit, or reject.
Deterministic extraction runs fast and predictably. 500k+ records, no AI per row.
Ask questions in plain English. Summaries, semantic search, and dashboards - instantly.
Legacy systems leave behind a mess - inconsistent formats, cryptic column names, data scattered across CSVs, emails, PDFs, and ancient databases. Archivist's AI samples your source data and automatically identifies every field, format, and relationship.

Archivist analyses the discovered data and proposes a clean, normalised database schema. Review column mappings, data types, and relationships before anything is extracted. Nothing runs without your sign-off.
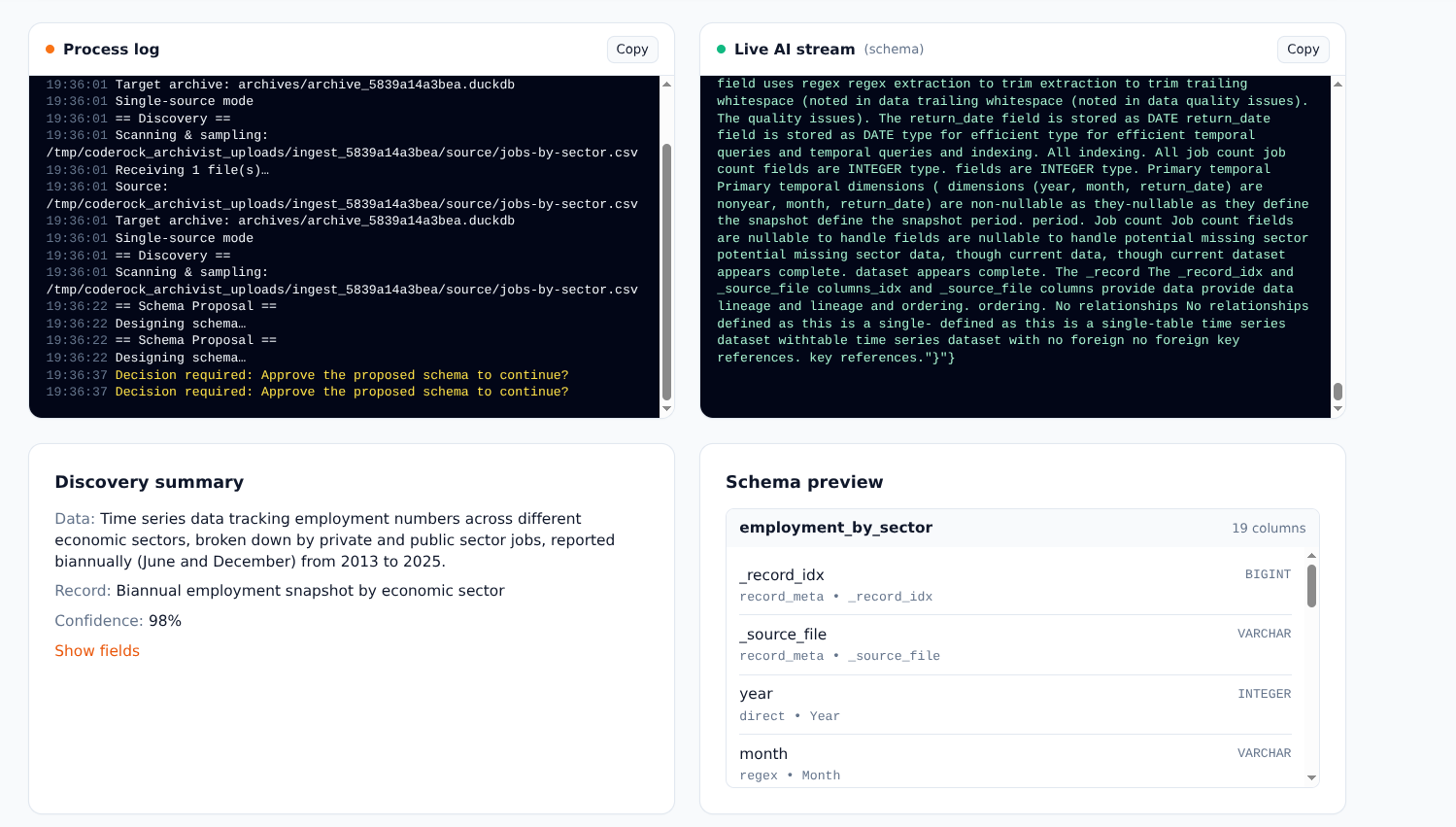
Once you approve the schema, extraction kicks off using compiled deterministic rules - no AI per record. This means speed, consistency, and zero hallucinated data. Quality issues are flagged for review, never silently ignored.
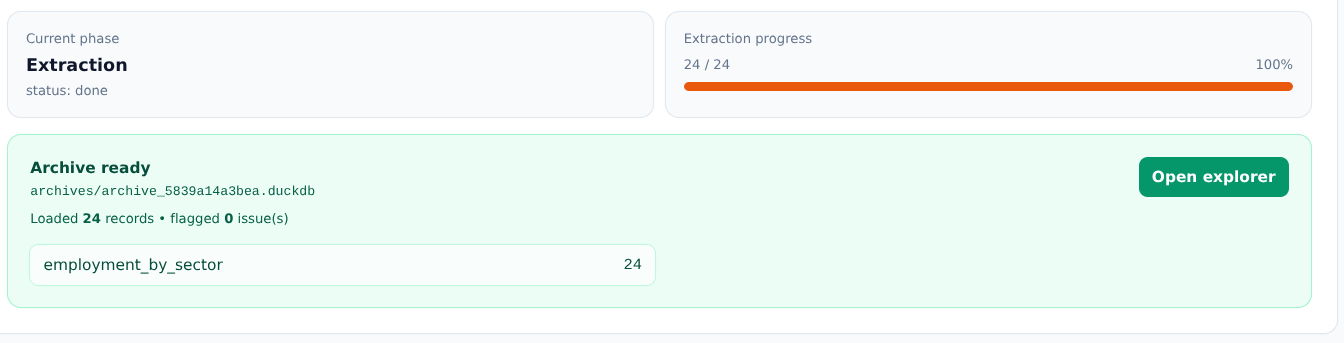
Once extracted, your data becomes fully searchable and queryable. Ask questions in plain English, explore with semantic search, or generate dashboards - Archivist translates your intent into SQL and returns results with visualisations.

Ask a question in plain English and get a clear, contextual summary drawn from across your entire archive.
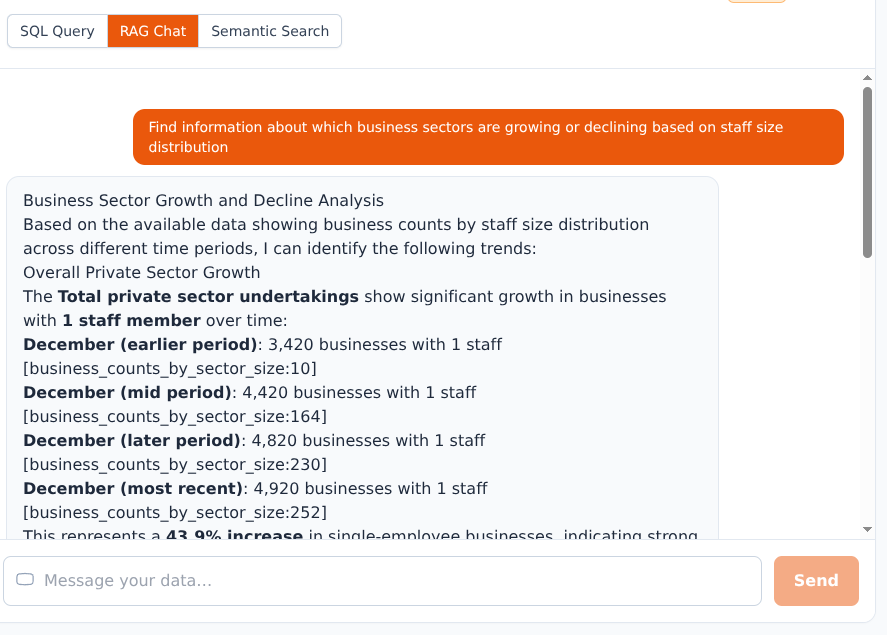
Find related records across the entire archive using meaning, not just keywords. Powered by retrieval-augmented generation.
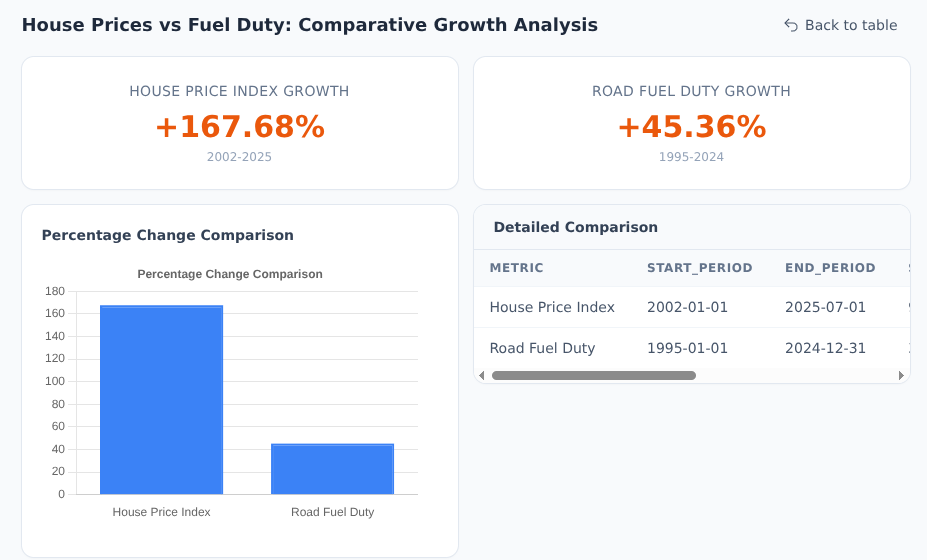
AI-generated charts, tables, and visualisations. Save and share dashboards with your team.
Legacy data is messy. Archivist is designed for exactly that.
CSV, email archives, JSON, XML, PDFs, spreadsheets - Archivist handles whatever your legacy system left behind. No predefined parsers needed.
AI proposes the schema, but you approve before anything is extracted. Review column mappings, data types, and relationships. Nothing runs without your sign-off.
Extraction uses compiled rules, not AI per record. Process 500,000+ records quickly and predictably. Quality issues are flagged for review, never silently ignored.
Your data stays on your infrastructure. Archivist runs locally, supports local AI models, and never sends your archive to the cloud unless you choose to.
Stop paying for months of ETL scoping. Let Archivist do the discovery in hours.
Get Started